


点击次数:828 发布日期:2022/12/27 来源:华斯泰
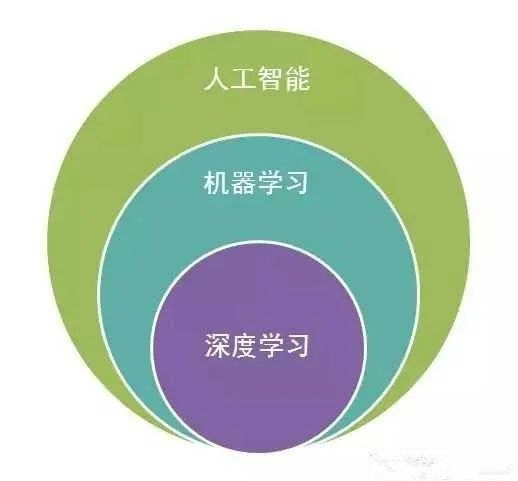
人工智能包括了机器学习和深度学习,机器学习包括了深度学习,他们是子类和父类的关系。
下面这张图则更加细分。
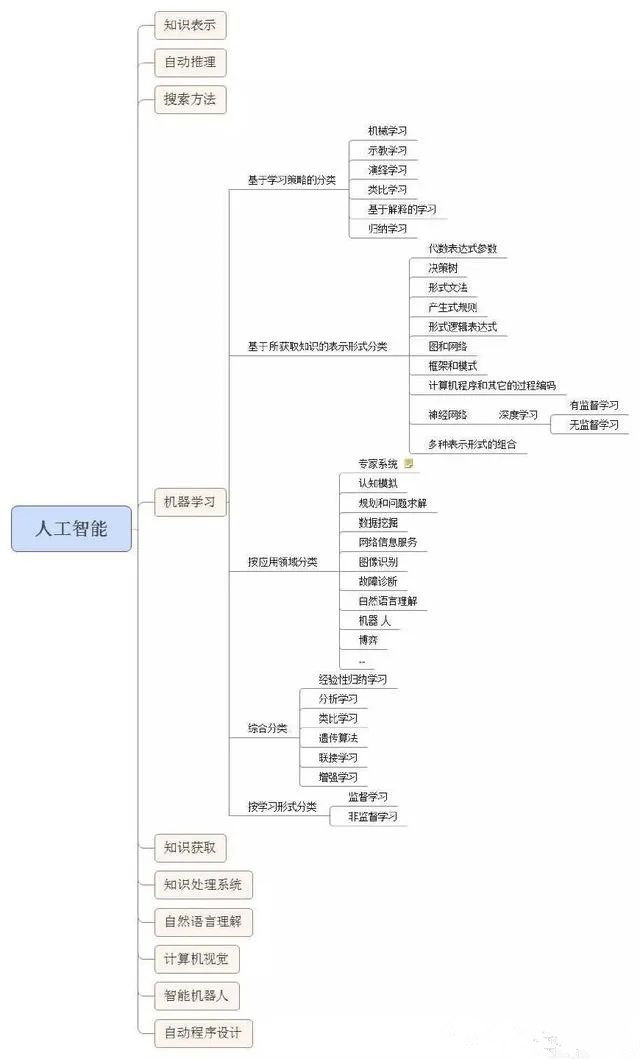
2、什么是人工智能
人工智能(ArtificialIntelligence),英文缩写为AI。是计算机科学的一个分支。人工智能是对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。数学常被认为是多种学科的基础科学,数学也进入语言、思维领域,人工智能学科也必须借用数学工具。
人工智能实际应用:机器视觉,指纹识别,人脸识别,视网膜识别,虹膜识别,掌纹识别,专家系统,自动规划,智能搜索,定理证明,博弈,自动程序设计,智能控制,机器人学,语言和图像理解,遗传编程等。人工智能目前也分为:强人工智能(BOTTOM-UPAI)和弱人工智能(TOP-DOWNAI),有兴趣大家可以自行查看下区别。
3、什么是机器学习
机器学习(MachineLearning,ML),是人工智能的核心,属于人工智能的一个分支。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。所以机器学习的核心就是数据,算法(模型),算力(计算机运算能力)。机器学习应用领域十分广泛,例如:数据挖掘、数据分类、计算机视觉、自然语言处理(NLP)、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用等。

机器学习就是设计一个算法模型来处理数据,输出我们想要的结果,我们可以针对算法模型进行不断的调优,形成更准确的数据处理能力。但这种学习不会让机器产生意识。
机器学习的工作方式
选择数据:将你的数据分成三组:训练数据、验证数据和测试数据。
模型数据:使用训练数据来构建使用相关特征的模型。
验证模型:使用你的验证数据接入你的模型。
测试模型:使用你的测试数据检查被验证的模型的表现。
使用模型:使用完全训练好的模型在新数据上做预测。
调优模型:使用更多数据、不同的特征或调整过的参数来提升算法的性能表现。
机器学习的分类
基于学习策略的分类
1、机械学习(Rotelearning)
2、示教学习(Learningfrominstruction或Learningbybeingtold)
3、演绎学习(Learningbydeduction)
4、类比学习(Learningbyanalogy)
5、基于解释的学习(Explanation-basedlearning,EBL)
6、归纳学习(Learningfrominduction)
基于所获取知识的表示形式分类
1、代数表达式参数
2、决策树
3、形式文法
4、产生式规则
5、形式逻辑表达式
6、图和网络
7、框架和模式(schema)
8、计算机程序和其它的过程编码
9、神经网络
10、多种表示形式的组合
综合分类
1、经验性归纳学习(empiricalinductivelearning)
2、分析学习(analyticlearning)
3、类比学习
4、遗传算法(geneticalgorithm)
5、联接学习
6、增强学习(reinforcementlearning)
学习形式分类
1、监督学习(supervisedlearning)
2、非监督学习(unsupervisedlearning)
注:细分的话还有半监督学习和强化学习。当然,后面的深度学习也有监督学习、半监督学习和非监督学习的区分。
4、机器学习之监督学习
监督学习(SupervisedLearning)是指利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。也就是我们输入的数据是有标签的样本数据(有一个明确的标识或结果、分类)。例如我们输入了50000套房子的数据,这些数据都具有房价这个属性标签。
监督学习就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的)。再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。就像我输入了一个人的信息,他是有性别属性的。我们输入我们的模型后,我们就明确的知道了输出的结果,也可以验证模型的对错。
举个例子,我们从小并不知道什么是手机、电视、鸟、猪,那么这些东西就是输入数据,而家长会根据他的经验指点告诉我们哪些是手机、电视、鸟、猪。这就是通过模型判断分类。当我们掌握了这些数据分类模型,我们就可以对这些数据进行自己的判断和分类了。
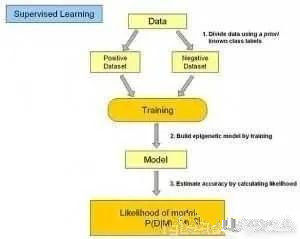
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
监督式学习的常见应用场景如分类问题和回归问题。常见监督式学习算法有决策树(ID3,C4.5算法等),朴素贝叶斯分类器,最小二乘法,逻辑回归(LogisticRegression),支持向量机(SVM),K最近邻算法(KNN,K-NearestNeighbor),
线性回归(LR,LinearRegreesion),人工神经网络(ANN,ArtificialNeuralNetwork),集成学习以及反向传递神经网络(BackPropagationNeuralNetwork)等等。
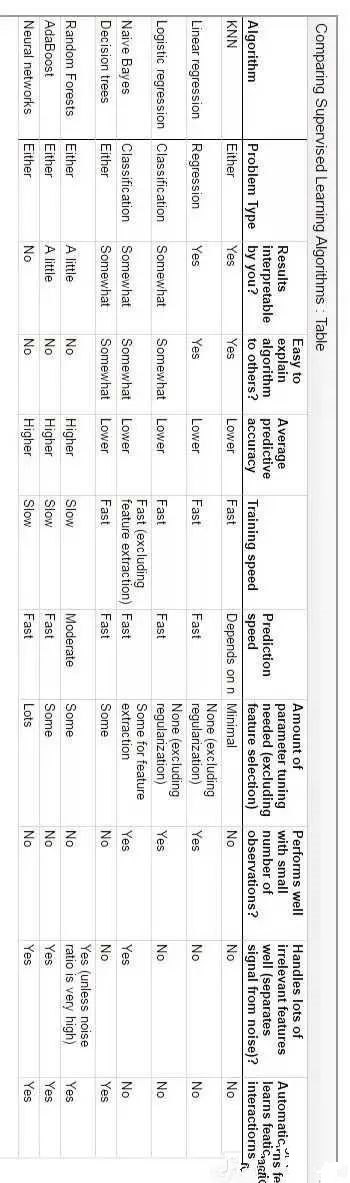
下图是几种监督式学习算法的比较:
5、机器学习之非监督学习
非监督学习(UnsupervisedLearing)是另一种研究的比较多的学习方法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模。是否有监督(Supervised),就看输入数据是否有标签(Label)。输入数据有标签(即数据有标识分类),则为有监督学习,没标签则为无监督学习(非监督学习)。在很多实际应用中,并没有大量的标识数据进行使用,并且标识数据需要大量的人工工作量,非常困难。我们就需要非监督学习根据数据的相似度,特征及相关联系进行模糊判断分类。
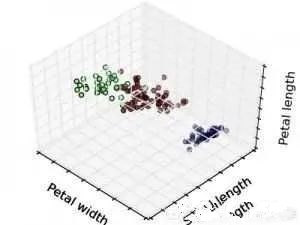
6、机器学习之半监督学习
半监督学习(Semi-supervisedLearning)是有标签数据的标签不是确定的,类似于:肯定不是某某某,很可能是某某某。是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。当使用半监督学习时,将会要求尽量少的人员来从事工作,同时,又能够带来比较高的准确性。
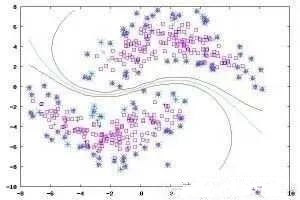
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。半监督学习有两个样本集,一个有标记,一个没有标记。分别记作Lable={(xi,yi)},Unlabled={(xi)},并且数量,L<
注:
单独使用有标记样本,我们能够生成有监督分类算法
单独使用无标记样本,我们能够生成无监督聚类算法
两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果
一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类,也就是在1中加入无标记样本,增强分类效果。
应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如自训练算法(self-training)、多视角算法(Multi-View)、生成模型(EnerativeModels)、图论推理算法(GraphInference)或者拉普拉斯支持向量机(LaplacianSVM)等。

